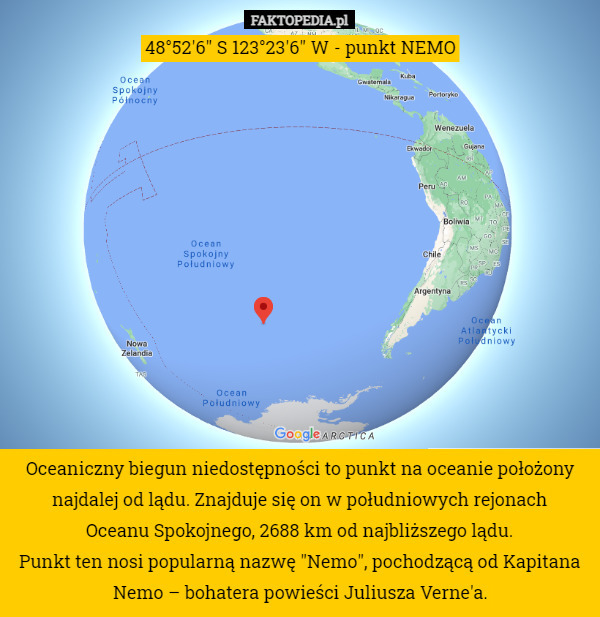
48 52 6 S 123 23 6 W

Understanding the pattern behind 48 52 6 s 123 23 6 w can help you decode structured sequences that appear in data logs, configuration files, or specialized formats.
Breaking Down the Components of 48 52 6 s 123 23 6 w
At first glance, 48 52 6 s 123 23 6 w looks like a random string of numbers and letters, but each segment often carries specific meaning in technical contexts. The numbers 48 and 52 could represent versions, years, or dimensional measurements, while 6 s might indicate a size, speed, or time increment. The presence of 123 and 23 suggests hierarchical identifiers or sequential steps, and the trailing 6 w may refer to a width, weight, or a time window expressed in weeks. By examining each token separately, you can start to reconstruct the logic behind this seemingly cryptic expression.
In data parsing, whitespace often serves as a delimiter, so treating 48, 52, 6, s, 123, 23, 6, and w as separate tokens is a logical first step. This kind of segmentation is common in configuration lines, log entries, or serialized objects where each token maps to a predefined field. For instance, 48 might map to a channel ID, 52 to a protocol version, 6 s to a buffer size, 123 to a transaction index, 23 to a subcommand, another 6 to a retry count, and w to a work mode or warning flag. Understanding these mappings is essential for anyone working with raw data streams or low-level system outputs.
Possible Origins and Use Cases
The sequence 48 52 6 s 123 23 6 w could originate from a wide range of domains, including networking, industrial automation, or software debugging. In network packet analysis, such strings sometimes appear as shorthand for header fields, where numbers denote port ranges, flags, or checksums, and letters indicate protocols or states. In manufacturing or IoT environments, similar patterns are used to encode sensor readings, batch numbers, or operational parameters, making it crucial for engineers to interpret each element correctly to ensure system reliability.
Another plausible context is configuration scripting, where compact notation is preferred to reduce file size and improve parsing speed. For example, a line like 48 52 6 s 123 23 6 w might define a preset in a firmware image, with each token controlling a specific hardware setting. Developers often design such formats to be both human readable and machine friendly, allowing quick visual inspection while remaining efficient for automated processing. Recognizing these patterns can save time when troubleshooting device configurations or reverse engineering legacy systems.
How to Interpret the Token 's' in Context
The letter s in 48 52 6 s 123 23 6 w is particularly interesting because it can stand for multiple concepts depending on the system. In many protocols, s denotes size, sign, or status, acting as a qualifier for the preceding numeric value. For instance, 6 s might mean 6 seconds, 6 samples, or a signed numeric format, and misinterpreting this character can lead to significant errors in data analysis. Therefore, always cross-reference such tokens with documentation or schema definitions to confirm their intended semantics.

When s appears between numbers, it often serves as a separator or a type indicator rather than a standalone value. Some systems use alphabetic characters to switch between modes, such as transitioning from read to write operations or from configuration to execution phases. In the case of 48 52 6 s 123 23 6 w, s might mark the boundary between numeric settings and alphabetic modifiers, helping parsers distinguish between raw data and symbolic instructions. This structural role is common in encoded messages where clarity and unambiguous parsing are priorities.
Relevance in Data Logging and Debugging
For system administrators and developers, encountering strings like 48 52 6 s 123 23 6 w is not uncommon when reviewing logs or debugging output. These sequences often act as fingerprints for specific events, allowing engineers to trace the flow of execution or identify where a failure occurred. By logging the exact format and context, teams can build patterns that help automate alerts or generate diagnostic reports. This makes such strings valuable indicators in complex, distributed environments where manual inspection is impractical.
Moreover, tools that visualize log data can highlight recurring tokens like 48 52 6 s 123 23 6 w, turning them into clickable elements that reveal deeper insights. Correlation engines may link these tokens across multiple sources to detect anomalies or performance bottlenecks. As systems grow more intricate, the ability to recognize and categorize these patterns becomes a critical skill for maintaining high availability and rapid response times.

Practical Tips for Working with Such Patterns
When you first encounter a string like 48 52 6 s 123 23 6 w, start by documenting its context, including the source application, timestamp, and surrounding lines. This metadata can reveal whether the sequence follows a fixed width format, a delimited list, or a hybrid structure. Next, compare it with known examples from the same system to identify consistent mappings for each token. Over time, you will build a mental model that allows you to decode similar patterns quickly and accurately.
Another best practice is to validate your interpretation by writing small scripts or using regular expressions that isolate each component and test its possible meanings. For example, you could check whether 48 and 52 fall within expected ranges, or whether w consistently appears in similar contexts. Automating these checks not only reduces human error but also makes it easier to onboard new team members who may encounter the same format in the future.
Conclusion
While the string 48 52 6 s 123 23 6 w may initially seem obscure, it becomes much more approachable once you break it into its constituent parts and consider the contexts in which such patterns arise. By analyzing each token, understanding the role of characters like s, and relating the sequence to real-world use cases, you can transform a mysterious line of text into a powerful source of insight. With careful observation and systematic decoding, you will be better equipped to work with complex data formats and improve both troubleshooting efficiency and system understanding.
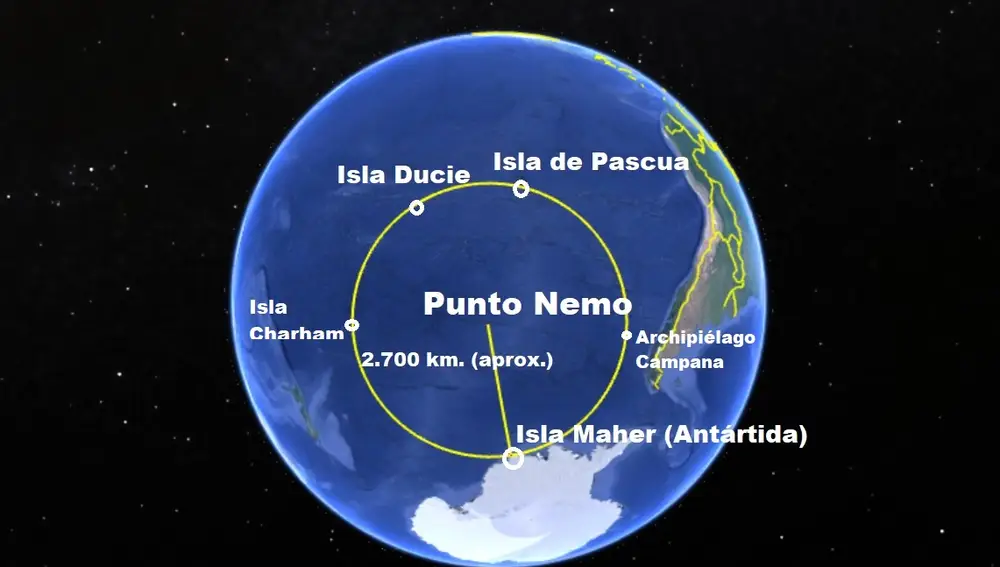
48°52.5′S 123°23.6′W
Listen everywhere: https://fanlink.to/fcYk Follow Denis Stelmakh: VK: https://vk.com/stelmakh_music Twitter: ...
