Em Um Sistema De Gerenciamento De Dados Uma Arvore Avl

Em um sistema de gerenciamento de dados, uma árvore AVL desempenha um papel fundamental para garantir que operações de busca, inserção e remoção sejam rápidas e previsíveis, mesmo quando os dados crescem exponencialmente. Trata-se de uma estrutura auto-balanceada que mantém a organização lógica dos itunes de forma que o custo de acesso permaneça próximo do ideal, minimizando desvios e retrabalho. À medida que bancos de dados, caches e sistemas de arquivos dependem de tempos de resposta estáveis, a árvore AVL surge como uma escolha inteligente para quem precisa de ordem sem abrir mão de performance.
O que é uma árvore AVL e como ela se relaciona com sistemas de gerenciamento de dados
Uma árvore AVL é uma estrutura de dados do tipo binária de busca na qual a diferença de altura entre as subárvores esquerda e direita de qualquer nó, chamado de fator de balanceamento, está restrito a -1, 0 ou 1. Isso garante que a árvore nunca fique excessivamente desbalanceada, o que poderia degradar o desempenho de varreduras e consultas. Em um sistema de gerenciamento de dados, essa propriedade de balanceamento automático é crucial para manter tempos de acesso estáveis, independentemente da ordem em que os registros são inseridos ou removidos.
Diferentemente de uma árvore binária de busca comum, que pode degenerar em uma lista encadeada em cenários extremos, a árvore AVL reorganiza seus nós por meio de rotações simples e duplas sempre que um desequilíbrio é detectado. Essas rotações preservam a ordenação in-order da árvore, ou seja, a sequência dos elementos continua logicamente a mesma, mas a altura total é reduzida. Para arquitetos de software que lidam com grandes volumes de informações, entender como uma árvore AVL se comporta em um sistema de gerenciamento de dados significa projetar camadas de acesso mais resilientes e previsíveis.
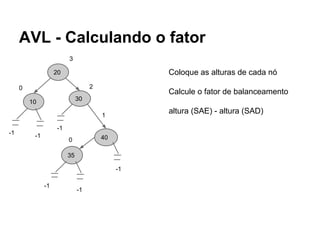
Balanceamento automático: a chave para manter a performance em escala
O balanceamento automático é o cerne da utilidade de uma árvore AVL em aplicações reais. Sempre que um novo nó é inserido ou um existente é removido, o algoritmo percorre os ancestrais do elemento alterado recalculando os fatores de balanceamento e aplicando rotações quando necessário. Existem quatro casos principais: rotação para a esquerda, rotação para a direita, rotação dupla esquerda-direita e rotação dupla direita-esquerda. Cada uma delas corrige um padrão específico de desequilíbrio, devolvendo à árvore a forma ideal para consultas subsequentes.
Em um sistema de gerenciamento de dados que trafega constantemente por essas rotações, o custo adicional de manutenção é compensado pela redução significativa no tempo de busca. Enquanto uma árvore não balanceada pode exigir percorrer praticamente todos os nós em casos ruins, a AVL limita a altura a aproximadamente log₂(n), onde n é o número de elementos. Isso significa que, mesmo com milhões de registros, o número de passos necessários para localizar um dado permanece relativamente pequeno, proporcionando uma respagem previsível para operações críticas.
Vantagens de usar uma árvore AVL em sistemas de gerenciamento de dados
A principal vantagem de integrar uma árvore AVL em um sistema de gerenciamento de dados é a garantia de desempenho consistente. Como o fator de balanceamento é verificado a cada modificação, a estrutura evita cenários de degradação progressiva que podem surgir com árvores comuns em entradas ordenadas ou quase ordenadas. Isso é especialmente importante em aplicações corporativas, onde a latência de acesso afeta diretamente a experiência do usuário e a capacidade de resposta do serviço.
Além disso, a previsibilidade da árvore AVL facilita a modelagem de custos em algoritmos que dependem de acesso rápido a índices, prioridades ou caches. Saber que o pior caso ainda se mantém O(log n) permite tomar decisões mais seguras na hora de dimensionar infraestrutura e planejar otimizações. Porém, é preciso avaliar com cuidado o custo de manutenção, pois rotações e atualizações de altura consomem processamento adicional em cenários de alta inserção e remoção frequentes.
Quando escolher uma árvore AVL em vez de outras estruturas
A escolha de uma árvore AVL em um sistema de gerenciamento de dados deve considerar o perfil de uso da aplicação. Se as consultas de leitura forem predominantes e a latência precisar ser estável, a AVL se destaca por oferecer tempos de busca muito próximos aos ideais. Estruturas como tabelas hash podem entregar desempenho médio O(1), mas carecem da ordenação inerente e do comportamento previsível da AVL, o que pode ser um problema para varreduras intervalares ou operações em faixas.
Outra alternativa comum é a árvore rubro-negra, que também se autobalanceia, mas com uma abordagem um pouco mais flexível, permitindo um desequilíbrio local moderado. Em cenários com inserções e exclusões massivas, a árvore rubro-negra pode apresentar menos rotações, reduzindo o overhead de manutenção. No entanto, quando a prioridade é minimizar a altura total e garantir o pior caso excelente para busca, a árvore AVL continua sendo uma das escolhas mais sólidas para engenheiros que projetam sistemas de gerenciamento de dados críticos.
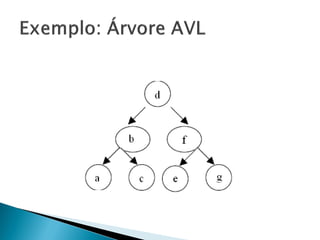
Implementação prática e boas práticas de integração
Implementar uma árvore AVL diretamente em um sistema de gerenciamento de dados exige atenção aos detalhes, desde a definição do nó até a rotina de balanceamento. Cada nó deve armazenar, além da chave e dos filhos, uma referência ao nó pai e o fator de balanceamento ou a altura da subárvore. Durante a inserção, após adicionar o novo elemento na posição correta, o algoritmo sobe pela árvore ajustando os fatores e aplicando rotações sempre que o desequilíbrio ultrapassar o permitido. Remoções seguem o mesmo princípio, exigindo verificação cuidadosa dos nós afetados.
Na prática, muitos desenvolvedores preferem utilizar bibliotecas ou frameworks que já oferecem uma implementação madura de árvore AVL, reduzindo riscos de bugs sutis. Em paralelo, é importante validar o comportamento com testes de carga e estresse, simulando padrões reais de acesso e verificando se os tempos de resposta permanecem dentro dos limites esperados. Combinar a árvore AVL com técnicas de cache, particionamento de dados ou estruturas complementares pode levar a um sistema de gerenciamento de dados ainda mais eficiente, sem abrir mão da robustez teórica que a AVL proporciona.
Conclusão
Em um sistema de gerenciamento de dados, uma árvore AVL oferece um equilíbrio sólido entre simplicidade teórica e eficiência prática, garantindo que operações críticas sejam executadas de forma rápida e estável, mesmo à medida que o volume de informações cresce. Sua capacidade de se autoajustar por meio de rotações a torna uma escolha sólida para aplicações que exigem previsibilidade de desempenho e acesso ordenado aos dados. Entender seu funcionamento, limitações e cenários ideais permite que engenheiros projetem soluções mais robustas, aproveitando ao máximo o potencial dessa estrutura icônica da ciência da computação.

O Que é Árvore AVL, Propriedades da Árvore AVL e Por que AVL é Balanceada | Estrutura de Dados #19
Neste vídeo, veremos o que é uma Árvore AVL, entenderemos a propriedade fundamental de uma Árvore AVL e mostraremos ...
