O Pyspark Caracteriza-se Como Uma Biblioteca Spark
O pyspark caracteriza-se como uma biblioteca spark que transforma a forma como engenheiros de dados e cientistas de dados interagem com grandes volumes de informação. Nascida sobre o motor robusto do Apache Spark, essa biblioteca de alto nível expõe uma API amigável em Python, permitindo que desenvolvedores escrevam pipelines de processamento distribuído de forma concisa e expressiva. Ao mesmo tempo, a pyspark herda a capacidade de escalabilidade horizontal e a performance em memória do Spark, o que a torna uma escolha natural para aplicações que exigem velocidade e resistência frente a cargas massivas de dados estruturados e não estruturados.
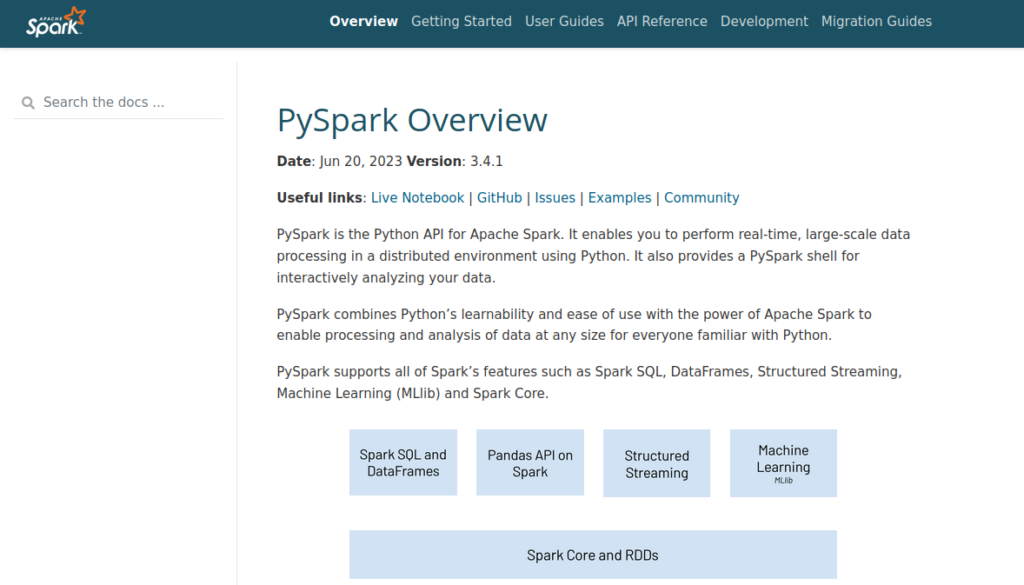
O que é pyspark e como ela se relaciona com o Spark
A pyspark nada mais é que a camada Python da engine Apache Spark, projetada para trazer a programação funcional e os otimizadores de consulta do Spark para o ecossistema de ciência de dados em Python. Enquanto o Spark é escrito em Scala e roda sobre a JVM, a pyspark atua como uma ponte, expondo componentes como Spark SQL, DataFrames, Datasets e Structured Streaming através de objetos Python. Dessa forma, a biblioteca permite que você aproveite todo o passo a passo de otimização físico-lógica do Spark, como o Catalyst Optimizer e o Tungsten Execution Engine, sem precisar escrever uma única linha de código em Scala ou Java.
Na prática, isso significa que você pode criar DataFrames a partir de fontes tão diversas quanto CSV, Parquet, bases de dados relacionais, Kafka ou até mesmo RDDs mais antigos, tudo com a mesma sintaxe intuitiva. A pyspark cuida da alocação de recursos, da distribuição de partições e da execução otimizada no cluster, enquanto você se concentra na lógica de negócio. Portanto, se você já domina Python, pode adotar essa biblioteca como ferramenta principal para explorar, limpar, transformar e analisar dados em grande escala com curva de aprendizado relativamente suave.
Principais componentes e APIs da pyspark
A pyspark é organizada em módulos distintos que cobrem praticamente todas as necessidades de processamento de dados em larga escala. Entre os componentes mais importantes, destacam-se Spark SQL para consultas SQL e leitura de fontes estruturadas, o Core com as abstrações de RDD, e as APIs de streaming, machine learning (MLlib) e graph (GraphX). Cada um desses blocos pode ser acessado de forma natural a partir da linguagem Python, graças à robusta implementação que a pyspark oferece como interface de alto nível.
- Spark SQL e DataFrames: fornecem uma visão distribuída de dados organizados em colunas, com otimizações automáticas de código e suporte a diversas fontes.
- Spark Core (RDD): a base original, ainda útil para controles mais finos de particionamento e operações não estruturadas.
- Structured Streaming: permite processar dados de entrada em tempo real com semântica de exatamente uma vez, unificando batch e streaming.
- MLlib e pipelines: facilitam a construção de pipelines de machine learning escaláveis, com pré-processamento, modelos e validação cruzada distribuída.
Essa modularidade é um diferencial importante, pois possibilita desde a ingestão bruta de logs até a entrega de modelos preditivos em produção, tudo dentro do mesmo ecossistema da pyspark. Você pode começar com um DataFrame simples e, conforme a complexidade aumenta, introduzir streaming, machine learning ou otimizações de custo sem precisar migrar para outra plataforma.
Vantagens de usar pyspark em projetos reais
Uma das maiores vantagens de adotar a pyspark está justamente na sua capacidade de escalar horizontalmente com relativa facilidade. Ao distribuir as operações por um cluster de máquinas, você quebra gargalos de memória e processamento que seriam intransponíveis em uma única máquina. Além disso, como a biblioteca lida com otimizações de código sob demanda, é comum ver ganhos de performance que chegam a ordens de magnitude comparados a abordagens puramente pandas ou SQL em uma única máquina.
![1. Introduzione a Spark e PySpark - Algoritmi di dati con Spark [Book]](https://www.oreilly.com/api/v2/epubs/9798341645103/files/assets/daws_0103.png)
A robustez da pyspark também se reflete na tolerância a falhas: o Spark cuida automaticamente de recomputar partições perdidas, garantindo que jobs longos não sejam perdidos por problemas transitórios. A curva inicial de configuração de clusters pode parecer desafiadora, mas, uma vez dominar os conceitos de partições, broadcast e shuffle, você ganha ferramentas poderosas para depurar gargalos e ajustar parâmetros de forma eficaz. No fim, o benefício de processar terabytes ou petabytes de dados com código enxuto em Python compensa amplamente o esforço de aprendizado.
Considerações sobre desempenho e boas práticas
Para extrair o máximo da pyspark, é essenciale entender como as operações são avaliadas sob o hood. Transformações como map, filter e select são executadas de forma preguiçosa, enquanto ações como count, collect ou write acionam a construção física do plano de execução. Dominar conceitos como particionamento, uso adequado de broadcast joins e o equilíbrio entre memória e disco ajuda a evitar gargalos clássicos, como shuffle excessivo ou OOM (out of memory). Além disso, gravar dados em formatos otimizados, como Parquet ou Delta Lake, reduz drasticamente o tempo de leitura e melhora a eficiência de armazenamento.
Outro ponto crucial é a versionamento e o gerenciamento de dependências, já que a pyspark costuma ser integrada a ambientes maiores que usam Databricks, Spark no local ou em nuvem (AWS, GCP, Azure). Utilizar ferramentas de controle de versões, testes unitários com pequenos conjuntos de dados e aproveitar os logs de execução ajudam a manter jobs mais previsíveis e manuteníveis. Invista também em monitoramento de métricas de Spark UI, que revelam insights valiosos sobre tempo de execução, consumo de memória e gargalos de rede, permitindo ajustes precisos sem precisar adivinhar.

Como começar a usar pyspark no seu dia a dia
Se você está começando do zero, a maneira mais simples de experimentar a pyspark é instalando o pacote via pip em um ambiente virtual e, se quiser algo ainda mais produtivo, usar o Databricks Community Edition ou um ambiente gerenciado em nuvem. Para testes locais, o modo local com dois ou mais núcleos já permite explorar toda a sintaxe de DataFrames, SQL e até mesmo micro batches de streaming. Pratique lendo arquivos pequenos, ajustando particionamentos e construindo pipelines modulares que possam ser reaproveitados em produção.
À medida que ganha confiança, pode evoluir para cenários reais de ingestão contínua, integrando Kafka, Delta Lake e sistemas de catálogo como Hive Metastore ou Unity Catalog. Explore também as funcionalidades de MLlib para levar seus modelos para o próximo nível, combinando pré-processamento escalável com treinamento e inferência distribuída. Com a pyspark, você não apenas processa dados mais rápido, como também constrói pipelines que são mais fáceis de escalar, monitorar e evoluir ao longo do tempo.
Em resumo, a pyspark consolida-se como a ponte ideal entre a simplicidade da programação em Python e a potência de processamento distribuído do Apache Spark. Seja para análise exploratória, ETL em larga escala ou aplicações de streaming e machine learning, essa biblioteca entrega performance, flexibilidade e uma curva de aprendizado acessível para quem quer ir além do pandas e do SQL tradicional. Ao adotar boas práticas e entender os princípios por trás de sua arquitetura, você transforma dados brutos em ativos estratégicos de forma rápida, confiável e escalável.
Eu Descobri o Segredo para Usar Spark com PySpark de Forma EFICIENTE
Neste vídeo, vou revelar o segredo para usar o Spark com PySpark de forma eficiente. Aprenda como usar o Spark para otimizar ...
